Explain How Big Data Processing Differs From Distributed Processing.
Distributed computing is different than parallel computing even though the principle is the same. Collection manipulation and processing collected data for the required use is known as data processing.

Eurasip Journal On Advances In Signal Processing Machine Learning Data Processing Big Data
International Journal of Distributed Sensor Networks 14 p11.

. Bigdata is a term used to describe a collection of data that is huge in size and yet growing exponentially with time. Big Data definition. Big Data processing is typically defined and characterized through the five VsThe volume of the data measured in bytes defines the amount of data produced or processed.
It splits the data into several blocks of data and stores them across different data nodes. Building Blocks of Hadoop 1. The velocity at which data are generated and.
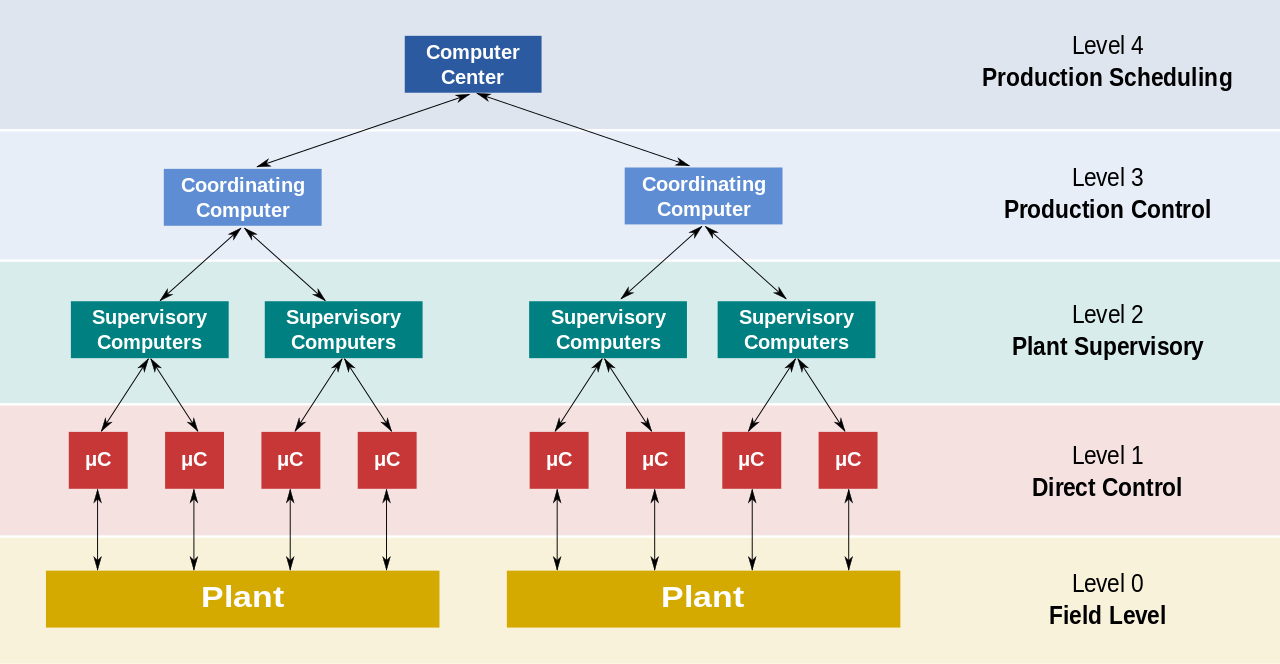
Distributed processing is a setup in which multiple individual central processing units CPU work on the same programs functions or systems to provide more capability for a computer or other device. Shuffles data to the right partition node thread hash or range Hash partitioning. These computers in a distributed system work on the same program.
Data preparation often referred to as pre-processing is the stage at which raw data is cleaned up and organized for the following stage of data processing. Distributed processing refers to. Difference between Parallel Computing and Distributed Computing.
Because the data is processed in a. Big Data can be defined as high volume velocity and variety of data that require a new high-performance processing. This arrangement is in contrast to centralized computing in which several client computers share the same server.
Distributed data processing DDP is a technique for breaking down large datasets and storing them across multiple computers or servers. Retrieve data from example database and big data management systems Describe the connections between data management operations and the big data processing patterns needed to utilize them in large-scale analytical applications Identify when a big data problem needs data integration Execute simple big data. The massive growth in the scale of data has been observed in recent years being a key factor of the Big Data scenario.
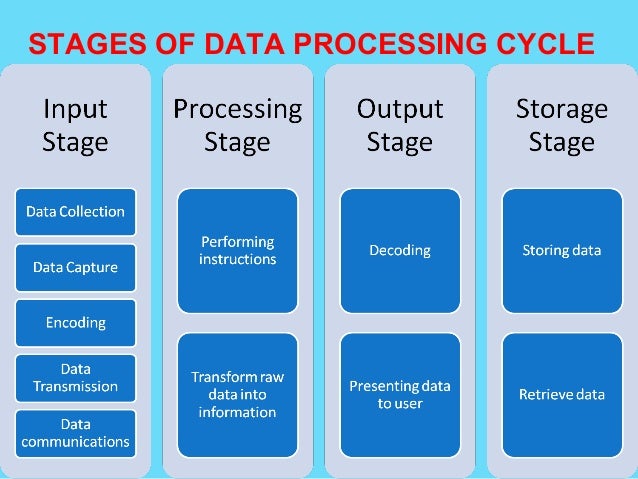
The Input of the processing is the collection of data from different sources like text file data excel file data database even unstructured data like images audio clips video clips GPRS data and so on. Addressing big data is a challenging and time-demanding task that requires a large computational infrastructure to ensure successful. During preparation raw data is diligently checked for any errors.
The whole idea of Big Data is to distribute data across multiple clusters and to make use of computing power of each cluster node to process information. Note that terminal is the combination of mouse keyboard and screen. The process includes retrieving transforming or classification of information.
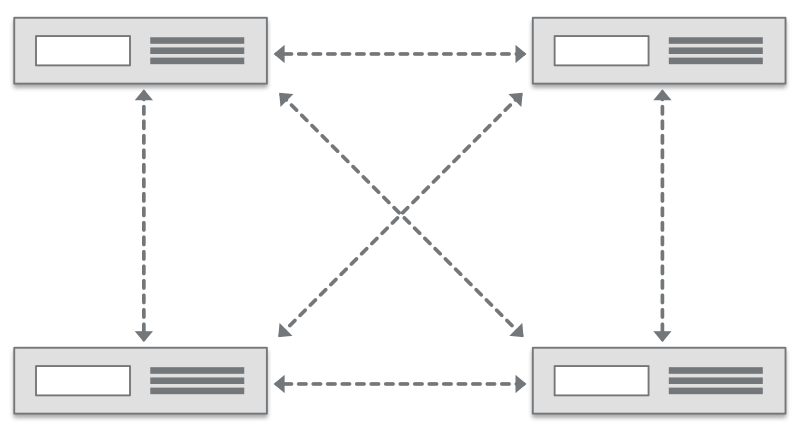
Distributed computing is a field that studies distributed systems. Big Data 11 pp5159. Changes in business practices eg a shift to the cloud and the application of techniques.
However the processing of data largely depends on the following. Centralized vs decentralized vs distributed processing. Big Data meaning a data that is huge in size.
The commonly available data processing tools are Hadoop Storm HPCC Qubole Statwing CouchDB and so all. In DDP specific jobs are performed by specialized computers which may be far removed from the user andor from other such computers. Organizing and Querying the Big Sensing Data with Event-Linked Network in the Internet of Things.
Data science is the study of data analyzing by advance technology Machine Learning Artificial Intelligence Big dataIt processes a huge amount of structured semi-structured unstructured data to extract insight meaning from which one pattern can be designed that will be useful to take a decision for grabbing the new business opportunity the betterment. An arrangement of networked computers in which data processing capabilities are spread across the network. In-library there is one processor attached to different terminals and library users can search any book from the terminal mouse.
Implementation of the Big Data concept in organizations possibilities impediments and challenges. See full answer below. It is a technique normally performed by a computer.
Memory in parallel systems can either be shared or distributed. Big Data could be 1 Structured 2 Unstructured 3 Semi-structured. Distributed file system is a system that can handle accessing data across multiple clusters nodes.
Parallel computing provides concurrency and saves time and money. Distributed systems are systems that have multiple computers located in different locations. At the end of the course you will be able to.
Innovative technology is not the primary reason for the growth of the big data industryin fact many of the technologies used in data analysis such as parallel and distributed processing and analytics software and tools were already available. HDFS The storage layer As the name suggests Hadoop Distributed File System is the storage layer of Hadoop and is responsible for storing the data in a distributed environment master and slave configuration. In centralized processing one or more terminals are connected to a single processor.
Partition_idrow hashkeyrow N Separation of concerns in distributed query processing Other operators are no different from single-threaded implementations eg. The purpose of this step is to eliminate bad data redundant incomplete or incorrect data and begin to create. Big data processing refers to computing against large data sets in particular using certain mathematical techniques.
Big Data analytics examples includes stock exchanges social media sites jet engines etc. In parallel computing multiple processors performs multiple tasks assigned to them simultaneously. In distributed computing we have multiple.
In this type of processing the task is shared by several resourcesmachines and is executed in parallel rather than being run synchronously and arranged in a queue. Philipp Neumann Prof Dr Julian Kunkel Dr in Knowledge Discovery in Big Data from Astronomy and Earth Observation 2020.
What Is The Difference Between Parallel And Distributed Computing Pediaa Com
Data Processing In Computer

Difference Between Cloud Computing And Distributed Computing Examplanning Distributed Computing Cloud Computing What Is Cloud Computing

Https Itcertinfographic Blogspot Com 2020 04 Hadoop Features Components Cluster Topology Html Distributed Computing Topology Data Science

Data Science Glossary What Is An Algorithm Data Science Data Science Learning Data Scientist

Here S An Interesting Infographic About The Difference Between Data Science Big Data And Data Analytics And Data Science Learning Data Science Data Analytics

Apache Flink Unifies Stream Processing And Batch Processing Stream Processing Data Science Streaming

Top 30 Big Data Companies Big Data Data Architecture Data

Hadoop Training Institute In Agra Big Data What Is Big Data Data

Parallel Versus Distributed Computing Distributed Computing In Java 9 Book

10 Reasons Why Big Data Analytics Is The Best Career Move Edureka Co Data Analytics Big Data Big Data Analytics

Cloud Computing Edge Computing Cloud Computing Technology Posters Technology Quotes

What Is The Difference Between Parallel And Distributed Computing Pediaa Com
An Overview Of Distributed Computing Hazelcast

To Manage And Capture Bigdata Traditional Methods Are Not Sufficient In Big Data One Has To Deal With Complex Voluminous Data And Big Data Data Science Data

Relationship Between Data Mining And Machine Learning Machine Learning Data Mining Learning Science

Mapreduce Is A Programming Model Suitable For Processing Of Huge Data Hadoop Is Data Science It Works Tutorial

Pin On Big Data Path News Updates

Big Data Processing An Overview Sciencedirect Topics
